接下來咱們要來談談,在應用層中很常提到的兩個池『線程池』與『連線池』,它們兩個在應用層扮演了性能方面什麼樣的角色。
本篇文章分為以下幾個章節 :
先說以一下,這裡不一定是指進程 process ,也有可能是指線程 thread,反正都是代表一個池子裡裝了這兩種東西。
接下來咱們以 process 進程為主。
進程 process 咱們已經在前幾章很常看到它,它的基本概念就是 :
作業系統的操作單位且是最小資源分配單位
也就是在某個時間,會以 process 為單位開啟資源,並將 cpu 分配給它來工作。
而所謂的進程池的就是,一個裝了一堆進程的隊列,當你有需要進程時,去裡面拿,而不用在重新建立一個新的。
先說一下,咱們什麼時後要開多個 process 或 thread 呢 ?
那為什麼需要進程池呢 ?
這裡後我們簡單的複習一下,看看建立進程與結束是要做那些事情。基本上就如下面這張圖一樣,就是不斷的拷貝記憶體或移除記憶體。請別小看這一段工作,事實上要做不少事情的。
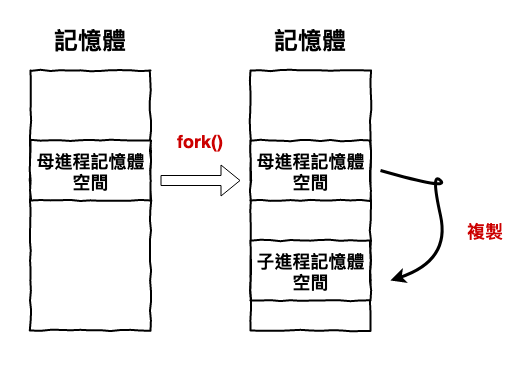
圖 1 : 建立進程的過程
你如果閒的話,可以使用以下的指令來看看建立一個進程它到底做了那些事情。下面指令 pid 為你要發起建立進程的 process 編號。由於輸出非常多的東西,所以這裡就不貼了。
sudo dtruss -p {pid}
接這咱們來簡單的看一下進程池的實務上有在用的範例。
有用過 php 的開發者應用知道這個東西 PHP-FPM ( FastCGI Process Manager ),看它名字就知道它是一個進程管理器,而且裡面就有所謂的進程池的運用。
咱們簡單的來理解一下它的概念。
php 有一種很常見的 web server 搭配組合如下。
nginx + php-fpm
而當有一個 http 請求時會如下流程運行。

其中進程池的應用就在於 php-fpm 那一塊裡面,每當從 nginx 收到一個 fast-cgi 協議請求後,它就會從進程池抓一個 worker 過來,實際上的處理 php 程式碼。
而這裡進程池就就節省了以下兩個耗資源的工作:
上述就是一個線程池應用實例的範例,基本上這個功能非常的常見,常見到正常來說大部份的開發者應該都是不知覺不覺的有使用到,但是這不代表咱們可以不用知道。
~ 小知識 ~
cgi 是一種協定,是為了讓 web server 與實際處理程式碼的地方的溝通管道,以 php 來說,發送一個 http 到 apache server 後它會透過 php cgi 協議來轉換讓 php 處理這請求的東西。
而如果要讓 apache server 就會透過 python cgi 來轉換讓 python 來處理, cgi 這東西在不少 http server 都有支援,例如 iis。
然後 fast-cgi 就是為了改善 cgi 缺點的東西,詳細請參考筆者下面這篇文章。
目前如果你上網查應該是會看到以下兩個配置數 :
這個數量還算合理,咱們應該都知道,在同一個時間下,一個進程只會被分配到一顆 cpu 工作,然後假設咱們進程池設 4 個,然後 cpu 1 個,那基本上同一個時間內最多只會有一個進程在工作。
這個使用數量有一個假設,那就是它是使用 multi thread 來處理 i/o 的情境,但如果是 reactor 模式情境,那事實上就可以考慮與 cpu 密集數一樣的就好,因為不在需要開多線程來等 i/o,而只要考慮你可能開線程來進行一些運算工作。
像 libvu 它開的 worker thread 就是根據邏輯 cpu 數來決定。
接下來咱們來談談『 連線池 』這東西,基本它的概念與上述線程池很相似,都是建立一個隊列,來存放東西,而它所存放的就是『 連線 』。
有以下幾個原因 :
基於以上幾個原因,所以才誕生連線池這個機制,而這通常在咱們常用的 mysql 與 redis 等應用非常的常見。
~ 小備註 ~
tcp 不熟的可以參考筆者這一篇文章。
那一個連線池需要開多少量呢 ?
這裡你要先有一個重要的觀點,在這裡的連線池除了為了性能以外,最重要的是為了 :
保護對像,不要讓它炸掉
連線池的確可以藉由減少建立 tcp 連線,來增加性能,但是它最重要的目的是為了保護對象,如果有十萬個用戶同時的連 db,應該是馬上炸掉,而如果連線池最大 size 只設一千,就代表同一個時刻只能有一千個請求進到 db,而其它的都在應用層慢慢的排隊處理。
接下來呢咱們要來看看你的應用層是如何的處理 i/o。前面的文章中咱們有提到處理 i/o 的模式有兩種 :
在有了這個觀念後,咱們就可以來評估看看連線池應該建立多少。
~ 小提醒 ~
如果還不太熟細 i/o 如何處理的,可以參考這幾文章。
30-07 之應用層的 I/O 優化 - 非阻塞 I/O 模型 Reactor
~ 小提醒 ~
正常的 connection pool 都有實作隊列的功能。
i/o 處理目前有兩種型式如下 :
先來談談傳統型,就是每一個 i/o 都需要開到一個 thread,而且假設咱們有開 thread pool 大小設為 20。
知道這代表什麼意思嗎 ? 就代表同一個時間最多只能有 20 thread,先不考慮 cpu 分配,這也代表你最多同一個時間只能發出 20 個請求。
所以這時你的連線池有準備 100 條請求,那事實上也完全的用不到。
接下來看一下 cpu,假設你的邏輯 cpu 有 4 個,然後預設最大有 20 thread,這事實上也代表這,同一個時間,能工作 thread 只有 4 個,也就是說能同時發送請求的數量最多也只有 4 個。
所以這時你的連線池事實上設 20 好像也不能說到很有用。
所以到了這裡會比較建議,就先根據邏輯 cpu 的大小來設個基準,然後如果你真的怕怕就再乘個 2 吧。
multi thread 有 pool 連線池量 = 邏輯 cpu + 變數
接下來談談第二型 reactor 非阻塞 i/o 模式,這種真的就是 i/o 發爽爽,沒啥限制,有的限制也只是會在對象身上。
refactor i/o 模式 連線池量 = 還不確定,要看對象。
~ 小知識 ~
Tomcat 就的 max thread pool 預設為 200,參考看看。
這裡咱們就以 mysql 為主來看吧,如果對象是 mysql 來看的話連線池量要開多少呢 ?
先說一個重要知識 :
mysql 是一個請求就會開一個 thread 來處理
所以假設 mysql thread pool 的最大 size 為 20,你應用層如果開了 40 條也是用不上。
那咱們接下來是不是考慮 cpu 的分配呢 ? 這裡我到覺得不用,因為對 mysql 工作來說有兩種,一種是可能是在運算,第二種是在等 i/o ,所以這裡應該是只考慮同時可以工作單位的量就夠了。而應用層需要考慮 cpu 是因為,我們要知道應用層可以同時的發送幾個請求。
接下來咱們來看一下 mysql 的幾個參數,如下。
SHOW VARIABLES like "%max_connections%";
max_connections : 100
SHOW VARIABLES like '%thread_pool%';
# Variable_name, Value
thread_pool_max_threads, 64
thread_pool_size, 16
從上述參數咱們知道,mysql 在連線量與線程池量都有設定限制,上面都是預設,你可以進行調整,要如何調整要依據你的機器性能來決定,這裡就不多談。
到了這裡咱們簡單的在選個數量,基本上會以線程池的最大量來當個基準數,不過先說一下這裡是指應用層為 refactor 為基準,而如果是 multi thread 則還是如上。
refactor i/o 模式 連線池量 = mysql thread_pool_max_threads + 變數 。
最後這裡提一下,如果在系統上線一段時間後,可以使用下面的指令來看一下最大的使用連線量,然後可以使用這個來調整你的連線池的大小來進行最適化。
SHOW STATUS LIKE "%Max_used_connections%";
Max_used_connections: 100
------------------------------------------
SHOW STATUS LIKE '%thread%';
# Variable_name, Value
Com_show_thread_statistics, 0
Delayed_insert_threads, 0
Innodb_master_thread_active_loops, 1520896
Innodb_master_thread_idle_loops, 377815
Performance_schema_thread_classes_lost, 0
Performance_schema_thread_instances_lost, 0
Slow_launch_threads, 0
Threadpool_idle_threads, 0
Threadpool_threads, 0
Threads_cached, 251
Threads_connected, 23
Threads_created, 274
Threads_running, 1
~ 小提醒 ~
這裡小提醒一下,在 mysql 事實上是有連線 timeout 時間預設是 8 小時,有些人會擔心應用層忘了關,所以會將它設小,但這時你要注意連線池的重置時間,如果這個時間太大,你的連線池就會一直重新建連線。
SHOW VARIABLES like "%wait_timeout%";
wait_timeout : 28800
上述咱們學習了應用層的兩個重要的池『 x 程池 』與『 連線池 』。
其中 x 程池所代表的可能是線程又或是進程,這裡對池來說概念都是一樣,然後在這裡咱們建議
『 x 程池』的大小公式為 :
cpu 密集工作 : 邏輯 CPU 數 + 小變數
多進(線)程型 io 密集工作 : 邏輯 CPU 數 * 2 + 小變數
refactor 型 io 密集工作 : 邏輯 CPU 數 + 小變數
而『 連線池 』則建議 :
多進(線)程 i/o 模式 : 邏輯 cpu + 小變數
而如果是 refactor 模式又會有兩種分支 :
refactor i/o 模式 + 對象層為 多進(線)程 i/o 模式 : 對象層的 thread pool + 小變數
refactor i/o 模式 + 對象層為 refactor i/o 模式 : 不知道也……
最後一種 refactor 加 refactor 這種模式,例如 nodejs 連 redis 這種,我還真不太確定有什麼公式可以當基準,找了好久,還有看到有說 redis 不用使用連線池的,這裡說實話我目前覺得項多只能用測試法來找出最適合你們系統的數量吧……
然後最後如果真的不知道設多少,只要記好咱們的準則 :
保護對象層,不要讓它炸掉
你們參考看看,有啥問題或解答可以 cue 我。我也很想知道最後一種有沒有什麼算法公式。
最後這裡說一下,在說進(線)程池時,有時後進程與線程會不小心混這用,請見諒,它們是不一樣,但是對池這個概念來說請把它們想成一樣。
在上述的步驟中,當 corotuine A 丟完 read 後,就會自已讓出控制權,轉成如下圖 3 所示,然後接下來由 corotuine B 開始做它的工作,最後當有請求回應時,在將控制權轉交給 corotuine B,這樣就完了一段請求囉。注意一下,這裡所有的控制都是由『 應用層 』自已處理。
"在將控制權轉交給 corotuine B" 是否應該改為 "在將控制權轉交給 corotuine A"?
這系列文章很實用,謝謝
嗯沒錯 ~ 的確寫錯了 ~ 感謝您 ~ 已改好
關於 連結池的結論想請教
多進(線)程 i/o 模式 : 邏輯 cpu + 小變數
為什麼 app sever 的 多進程io模式,不需要考慮 db server 的 thread pool ?
假設一種極端的情況 app server cpu 32核,db server cpu 8核
依照您說的 connection pool size 依據 app sever 的 規格訂為 32
同時 32個 連線 送到 db server,但 db server 只有 8 個 thread 可以同時處理
其他多的 32-8=24 個連線
如果沒有開啟 thread pool 因為社群版不能用
在 db server 反而 變成 context switch 的負擔
這樣似乎沒有比較好?
若換成另一個情況 app sever cpu 8核,db server cpu 32核
pool size 採用 app server cpu 數量
每次 8個 app thread 從 pool 拿取 8個連線送出
等待連線回應的期間(阻塞),cpu 切換另外 8個 thread 進行工作
因 pool 沒有連線可拿,所以發生阻塞
但 db server 效能足夠,連線很快回應
app thread 阻塞情況應該不明顯
pool size 採用 db server cpu 數量
每次 8個 app thread 從 pool 拿取 8個連線送出
等待連線回應的期間(阻塞),cpu 切換另外 8個 thread 進行工作
再從 pool 拿 8個連線送出
但 db server 效能足夠,連線很快回應
可能 pool 中,某些連線永遠不會被取用
不確定自己的想法是否有錯誤的地方
可能實際上還是要做實驗才知道
想聽聽您的想法
是否應該看 db server 及 app server 哪個 cpu 數量少
就拿來當 連線池的大小?
參考來源
https://www.exception.site/essay/how-to-set-the-size-of-database-connection-pool
呃不好意思 ~ 完全忘記回應你了…… 真抱歉 ~ 我覺得你說的有道理呢 ~ 多進(線)程 i/o 模式這個地方我要重新的來修改一下。
感謝你囉 ~
等到您的回覆了xd
期待您新的內容

